SpotTrack: Award for Design Excellence
Every year The Norwegian Design Council / The Norwegian Centre for Design and Architecture acknowledges â€the very best of innovative solutions†through the annual Award for Design Excellence.
This year, SpotTrack, a product that I have been involved in designing, received one of the awards. SpotTrack is a laser-based reference system for relative positioning at sea, or, in plain words: a system that measures and tells you how far away you are from other ships and oil rigs.
SpotTrack has been developed by Kongsberg Seatex in collaboration with Halogen and Inventas. I worked on this product together with several other designers in Halogen. It is rewarding and fun to see that our efforts have resulted in a product that both the customers and the designers appreciate!

SpotTrack in use. Photo: Peder Torget
VizBox Bergen og årets geogründer
Geomatikkdagene 2015 gjekk av stabelen 17.-19. mars på Lillehammer. Geomatikk handlar om å kombinere tradisjonelle kartfag med informasjonsteknologi, som inkluderer alt frå oppmåling og datainnsamling til presentasjon av data på kart.
Fem geogründerar var inviterte til konferansen for Ã¥ presentere prosjekta sine, og eg presenterte eksperimenta eg har gjort med projisering av grafikk på 3D-printa terrengmodellar. Det var mange spennande prosjekt, men etter avstemminga var eg den heldige som vart kÃ¥ra til ‘Ã¥rets geogründer’! Hurra!
The VizBox Experiments
Eg presenterte både nye og gamle eksperiment. Under kan du sjå dei første eksperimenta, der eg tok utgangspunkt i eit 3D-printa kart over Sør-Noreg og bygningskomplekset til School of Cinematic Arts i Los Angeles:
VizBox Bergen
I tillegg presenterte eg nokre nye eksperiment der eg har tatt utgangspunkt i Bergen by og omegn:
I tillegg til heder og ære var premien Ã¥ fÃ¥ delta gratis pÃ¥ Geomatikkdagene 2017 – og det gledar eg meg til!
Fulbright report: six months at the School of Cinematic Arts in Los Angeles
As an interaction designer and researcher, I have always been fascinated by the power of visual communication and moving images in particular. Therefore, I was thrilled when I got invited to visit the School of Cinematic Arts at USC in Los Angeles for six months in 2013-2014. So, what happens when you put an introvert Norwegian in Los Angeles for half a year?

From Hollywood celebrities to traffic jam
For Norwegians, Los Angeles is probably most known for Hollywood movies and celebrities, in addition to beautiful beaches and palm trees. However, Los Angeles is extremely diverse. As one of the locals expressed it, Los Angeles is more like a salad bowl than a melting pot: different cultures and traditions exist alongside each others in stead of blending together. From Korea town to Bevery Hills, Downtown to Santa Monica – these are all sub-cities that apparently exist completely independent of each other.
Another obvious aspects that characterizes LA, is its car culture. It seems like everyone you talk to in LA have a car, and spend 1-3 hours each day just to get between home and work. Only one person in each car, of course! The traffic is overwhelming. For this reason, the first impression of the city can be quite harsh, but as you start to know different areas and spots in the city, it’s hard not to fall in love with it.

Introverts in LA
I was traveling to the US together with my husband, who was visiting UCLA as part of his PhD studies in cell biology. We both consider ourselves introverts, and consequently we were slightly anxious about how we would fit in, considering that LA is known for its outgoing and extrovert culture.
However, we quickly learned to appreciate the small talk in the shops, colleagues introducing us to their coworkers, and the including atmosphere in general. (And by the way, there are introvert people in LA as well, believe it or not!).
In addition, we were lucky to make friends with some of the locals quite early on, who brought us to cosy restaurants, beautiful hiking trails and intriguing exhibitions, and included us in American traditions such as Thanksgiving.
It’s all about the story
If I have to choose one word that summarizes the professional insight I gained in LA, it is the word ‘storytelling’. Everywhere you go in LA, from cafés to offices, from parties to academic seminars, people are talking about storytelling, as well as enacting it.
Considering that 120 000 people are employed in the entertainment industry in LA, this might not come as a big surprise. However, storytelling is not necessarily about creating the next Hollywood blockbuster; it might as well be used as a tool for creating engaging real world experiences or stimulating social change. If you have ever been to Disneyland, you know what I am talking about: everything is planned, staged and choreographed from beginning to end.
Storytelling is about telling an audience or reader how something happened to someone through a series of events. There is often some sort of conflict in the story, something that craves our attention. As a result, people are engaged and able to relate to what you have to say. Some researchers even claim that our brains are ‘hardwired’ for stories. Through storytelling, we can not only entertain people, we can also convey information and explain complex issues. Is seems to me that academics and researchers in particular have much to learn from storytellers.

Visiting the School of Cinematic Arts
The School of Cinematic Arts at USC is often ranked as the top educational institution for movie makers in the world. However, the teaching and research at the school deals with all kinds of ‘world building’ beyond movies, including computer games and other forms of interactive experiences across various media platforms.
The faculty at the school are hard working, teaching as well as doing research. It was striking to discover how many of the teaching staff combine their job at the university with entrepreneurial work such as consulting, movie making, running a shop, or starting a new business. The American Dream is very much alive, obviously generating a lot of creativity, knowledge and value. For example, one of the highlights of our stay in LA was an event at the bottom of an empty swimming pool, hosted by a company started by one of my colleagues at USC.
Data visualization and 3D printing
The aim of my research at USC was to explore interactive data visualization. During my stay I participated in several classes as well as research projects. The main outcome of my stay was a physical platform for interactive data visualization, which I called the ‘VizBox’. The VizBox combines 3D printing, projection mapping and gesture interaction. In order to document and convey the potential of such a platform, I created a video that demonstrates some of its possibilities.
Home, sweet home
Back in Norway, I am filled with gratitude for everything I got to experience in the US, and the friends I have made along the way. But being away from Norway for so long also made me appreciate how everyone in Norway have more or less equal opportunities – be if for education, healthcare or marriage. This is something we tend to take for granted. So be it that we might not be as good at storytelling, small talk and entrepreneurship as the angelenos.
The VizBox Experiments
This is the result of a project I have been working on for the past months. The video demonstrates the setup and use of the VizBox (previously known as TopoBox) – a physical platform for interactive data visualization on three-dimensional surfaces.
The project has been highly explorative, geared towards testing and demonstrating new potentials rather than producing a finished product ready for use. Hopefully, this can serve as a starting point for new discussions, projects and experiments.
I do not currently have any specific plans for developing the VizBox further. However, I would be happy to discuss ideas and possibilities for collaboration. What would YOU do if you had a box like this?
Update march 2015: I have made a new prototype and video, and won a prize for the work! See the new blogpost: “VizBox Bergen og Ã¥rets geogründer” (in Norwegian).
Credits
- Funding from Fulbright
- Elevation data and geographic data from The Norwegian Mapping authorities
- Norwegian municipalities in GeoJSON by Ove Daae Lampe
- Statistical data from Statistics Norway
- Survey data from Difi
- Music: All Night by Sliptide
- Made with Processing and the Unfolding Maps and LeapMotionP5 libraries.
Special thanks to colleagues and students in the Media Arts + Practice program within the School of Cinematic Arts – especially Virginia Kuhn, Andreas Kratky and Behnaz Farahi.
TopoBox: exploring a tangible dataviz platform
A lot of exciting examples of interactive data visualization projects are popping up on the web these days. Many of these are interactive, and allow the user to navigate or filter information using a mouse or a finger on a touch screen. But what might the future of interactive data visualization look like?
Even though touch screens might seem perfect for interacting with computers, they are far from perfect. As pointed out by Bret Victor, our screens force us to interact with pictures under glass, and don’t allow us to make use of our full range of capabilities for perceiving and interacting with tangible objects. After all, we are experts at interacting with real-world objects that have physical properties like texture, translucency, elasticity and weight.
Science fiction movies and holographic displays
If we look to science fiction movies (which often give us a glimpse into possible futures of interface design), it seems like the future is going to be filled with large, immersive holographic displays. Even though many of these envisioned interfaces don’t seem very usable or even useful, there is obviously something immediate and engaging with the presentation of graphics in three-dimensional space, integrated with our physical environment. For example, such interfaces would allow multiple users to see and explore three-dimensional data from multiple angles.
Still image from Avatar. Image: inventinginteractive.com
While there have been a lot of interesting developments in holographic display technology in recent years, for example by the Graphics Lab at the University of Southern California, I believe we have a long way to go before high quality holographic displays will be available outside high tech labs.
Virtual Reality and Augmented Reality are probably more likely to be successful, but they come with a big disadvantage: they provide un-social interfaces. AR and VR typically place the interface in front of users’ faces, thereby obstructing social interaction between the user(s) and other people. In contrast, the holographic displays portrayed in science fiction movies like Avatar are social; they allow multiple users to seamlessly interact with the information and each other.
However, even if holographic displays were cheap and available, they would not provide any haptic feedback and data with material qualities. What if we could find a way to combine haptic interaction with spatial, three-dimensional graphics, and thereby create a new medium for data visualization, using commonly available and affordable technology?
Case: a topographic map of Norway
While I was working with survey data from Difi a while back, I was sketching out different ideas for creating interactive data visualizations using the data from Norway.
One of the ideas that emerged was to build a physical box with a topographic landscape of Norway on top of it, onto which graphics could be projected from inside the box. For practical purposes the graphics could be projected onto a mirror in the box from one of the sides, as shown in the illustration below.
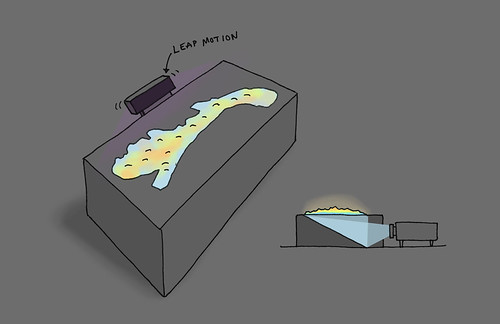
By attaching a Leap Motion sensor to the box, the users would be able to interact with the visualization using gestures, for example pointing to specific places to open more information on an adjacent screen, or make a swipe gesture above the box to go to the next visualization. If rear-projection is used, there will be no shadows from the hands, which often is a problem when front projection is used.
Obviously, this surface does not provide the same flexibility for 3D graphics that a holographic display would do. But for specific applications it might be superior to holographic displays, because of its physical manifestation and tangibility. And more importantly, this platform can be put together using commonly available and fairly cheap technology.
Initial experiments: projection on 3D printed surfaces
3D printing is perfect for creating complex surfaces. However, I wasn’t sure how rear projection would work with the 3D printed material, so I needed to start off by doing some simple experiments. I ordered some sample models with different thickness from Shapeways, including one representing buildings in a cityscape, and projected graphics onto them.
The result wasn’t as good as I hoped for, but not too bad either. I was especially happy to see how effective it is to see movement on a curved, physical object. Kind of magic, don’t you think?
As expected, the quality of the graphic is best using front projection. However, if the surface is thin (less than 1mm), rear projection works quite well, if not for the most detailed graphics.
After much struggle, I also managed to create and print a 3d model of the southern part of Norway:

Note that the elevation has been exaggerated. Otherwise, it would probably be impossible to see any fjords or mountains at all. After all, the aim here is not to reproduce a perfect scale model, but rather a physical representation that is as informative as possible.
A rough mockup to test the rear projection via a mirror in a box:

Finally, the result:

Even though I found these experiment promising, it is clear that I need to print a larger model in order to get higher graphical resolution. In addition, I think I need to exaggerate the elevation even more.
Further work and remaining questions
As you probably can guess, this work is highly experimental, including a lot of trial and error. This can be quite frustrating at times, and I am not sure how good result it is possible to get using 3D printing and rear projection.
Probably, this new ‘medium’ will turn out to work well for some types of visualizations, and not for others. What are the design affordances of such a medium? What kind of data would you like to see projected onto such a physical landscape? How would you interact with it?
Search
Recent posts
- SpotTrack: Award for Design Excellence
- VizBox Bergen og årets geogründer
- Fulbright report: six months at the School of Cinematic Arts in Los Angeles
- The VizBox Experiments
- TopoBox: exploring a tangible dataviz platform
- Norway in 3D part I: from DEM to 3D surface
- Using visualization for understanding survey data
- Story kicking big data
- Fulbright project: Dynamic Information Visualization
- Visiting Fulbright scholar at USC in Los Angeles
- (E)motional design paper at DANDE2012
- 3,5 års arbeid på 6 minutt og 40 sekund
- PhD thesis online
- New video: Kinetic Interface Design
- Presentasjon: Skisser utanfor boksen