census
Using visualization for understanding survey data
One of the goals for my Fulbright project has been to work with real data, and use visualization as a means of exploring, understanding and analyzing data.
When doing research on data visualization it is obviously necessary to have some data to work with. Before going to the US I decided to cooperate with Difi (The Agency for Public Management and eGovernment) in Norway, since I had positive experiences from working with them before, and they were more than happy to see someone use their data.
More specifically, I have been working with survey data from The Norwegian Citizen Survey (Innbyggerundersøkelsen), which asked 30.000 Norwegians about their perceptions of public services in Norway, the welfare state and democracy, and living in different parts of Norway.
I have carried out a range of visualization experiments in order to get to know the data, but also for testing different visualization techniques as tools for discovery and analysis. Some of these visualization experiments will be presented in this blogpost, along with some of the lessons I have learned on the way.
Gigamapping the survey
One of the challenges when facing a large dataset is to understand the context in which it has been created. How was the data gathered? What can the data tell us, and more importantly, what can it not tell us? Are there any specific issues that are important to be aware of when analyzing and presenting the data?
Before leaving Norway, I had a meeting with the people in Difi that are responsible for the survey. While discussing the survey, I made notes on a large canvas laid out on the table, which served as a medium for documentation as well as a shared platform for discussion during the meeting. The resulting sketch was messy and kind of ugly (as expected!), but served its purpose well.
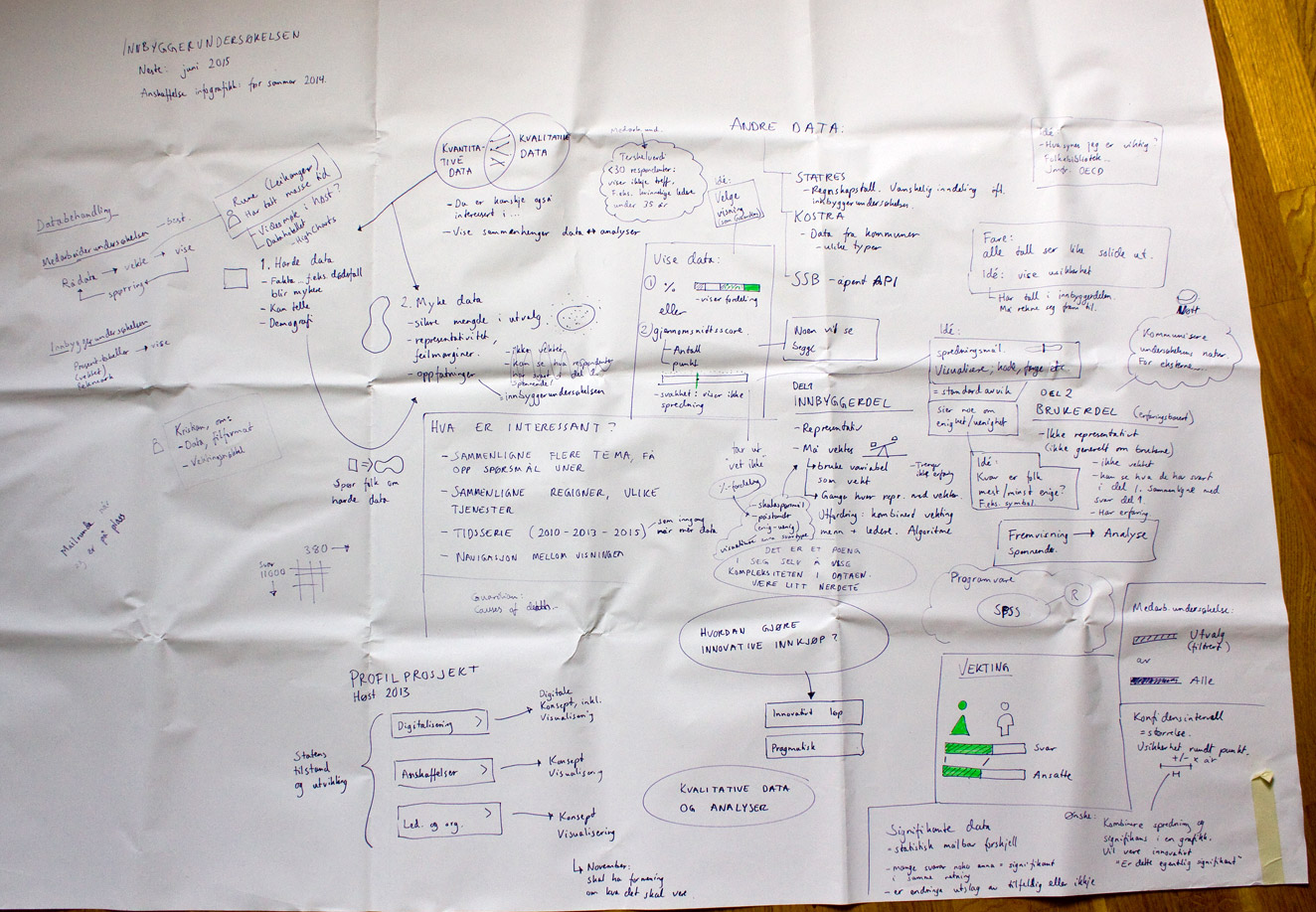
Sketch from meeting with Difi. Click to see larger image.
When I got to the US I digitized and cleaned up the map, and added some more relevant information. The result is a visual overview, or gigamap, that maps out different aspects of the survey and the data, and also serves as a medium for discussing the project with Difi and others. For me, the process of making the map was probably as important as the resulting map itself, as this forced me to clarify and reflect on the information, and look deeper into areas that I didn’t know enough about (like relevant concept from statistics).
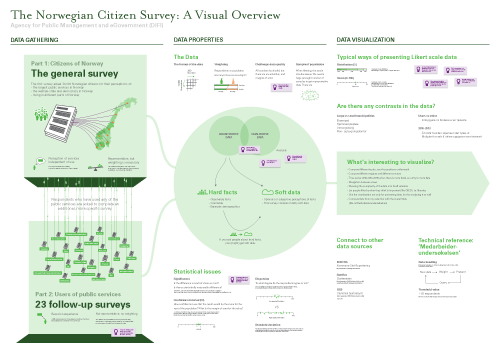
Digitized and cleaned gigamap. Click to download map in PDF format (1.6 MB). Feel free to print it out and put it on the wall, like I did!
I have put the final map on the wall in my office to remind myself of all the aspects of the survey, as well as make my project visible to my colleagues. In addition, it has been useful to show the map in presentations, and literally zoom into specific areas of interest.
Lesson learned: Visualization and gigamapping can be useful for gathering, processing and communicating information about the context in which a specific dataset has been created. One of the main challenges is to find the balance between complexity and simplicity, between visualization as a tool for thinking and visualization as a tool for communication.
10,039,380 data points
After my initial meeting with Difi, it was time to get to know the data. When I have visualized data before I have mostly worked with aggregated data that has already been processed. In this case, however, I wanted to work with raw data in order to get more control and better understanding of the data.
The survey data comes in a large spreadsheet format in which each respondent’s answers are located in a row, and each column represents an answer to a question (or data about the respondent). For just part 1 of the survey there are 23790 rows and 422 columns, which results in 10,039,380 cells! Where to begin?
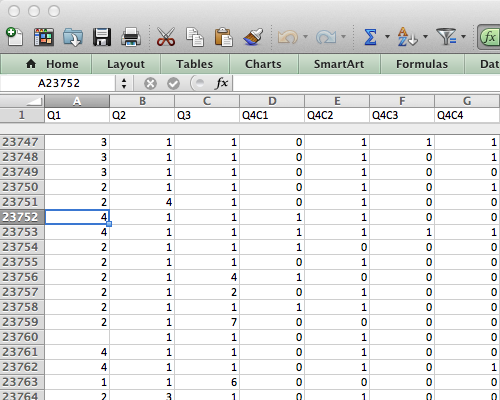
Screenshot from Excel
Lessons learned: it can be quite overwhelming to approach a large dataset for the first time. Even though working with ‘raw data’ has its advantages in terms of pliability, it requires specific knowledge and skills to approach it efficiently.
First attempts: Tableau Public
My first attempts for working with the data were done with Tableau Public, the free version of Tableau Software.
Tableau Software is an application designed specifically for data visualization, and provides an (seemingly) easy-to-use interface. Unfortunately Tableau only runs on PCs, so I had to install Windows on my Mac to try it out. (A Mac version of Tableau Public is coming out in 2014).
I have the impression that many dataviz designers use the software for discovery, so I wanted to give it a try. However, I found that the type of data I work with (survey data that should be weighted) was hard to get into Tableau. Finally, I managed to get some of the data in, and I was able to gain some insight from the resulting visualizations. For example, I found that people in Norway are overall satisfied with their life situation – which of course is a good thing, but not so interesting to visualize!
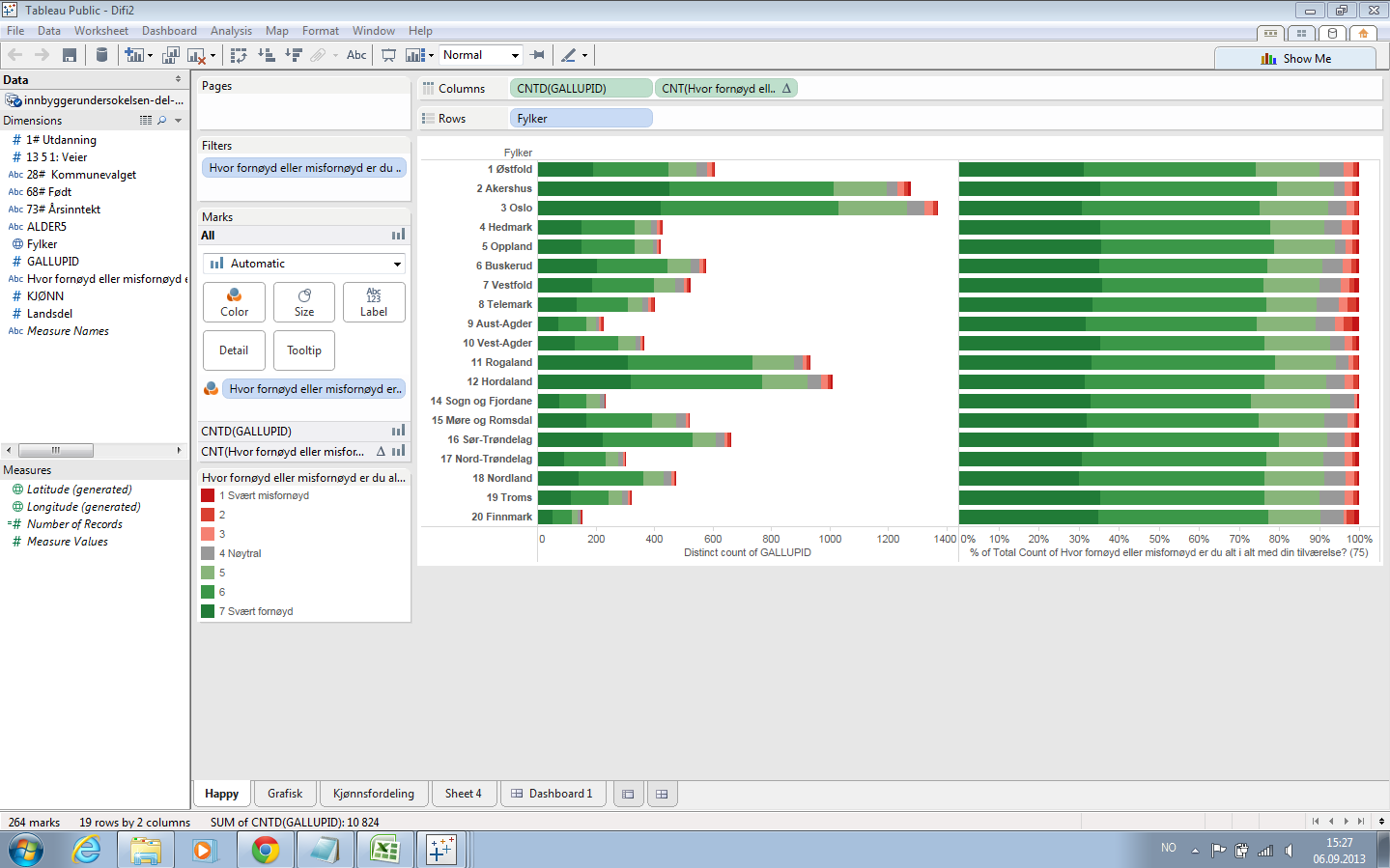
Screenshot from Tableau Public. Click to see larger image.
Lesson learned: the good and bad thing with tools like Tableau is that the software presents you with a limited set of visualization types. This is useful if you need a standard graph, but Tableau is not the software package you would choose for exploring new kinds of data visualization. In addition, Tableau seems to live in its own little bubble; you have to work with the presets, interface styles and export formats presented to you. I needed something more flexible, and didn’t want to spend a lot of time learning to use an application that could only take me so far.
Going behind the scenes with Python
While struggling to get my data into Tableu, I realized that I needed to learn some new tools to be able to sort and rearrange data. In addition, I wanted to combine several datasets into a new one, and for that purpose I needed to do some scripting.
Inspired by Nathan Yao, I decided to learn Python, which runs in the Terminal, and is powerful for working with large datasets. Python is also useful for scraping websites for data, which might come in handy later. If you want to learn Python, I highly recommend CodeAcademy. But be warned: you might get addicted to its game-like learning environment! I did.
Lesson learned: preparing, sorting, merging and rearranging data is a necessary but time consuming part of the data visualization process. Even though a couple of lines of code might be enough, the challenge is to find out exactly what those lines should contain. I am convinced that dataviz designers should learn at least some programming.
Categorical data overview with dbcounter
Since I started working with the survey data, I was looking for a way to get an overview of all the data. The solution was a Nodebox script written by Moritz Stefaner, that quickly makes a visual overview of large sets of categorical data (like survey data). I downloaded Nodebox and the script (which is written in Python), and tweaked it a bit. I saved the resulting illustration as a PDF, and changed the colors and fixed the text in Illustrator.
Each row shows the distribution of the responses for each question in the survey. Next to the graphic I put all the questions, so that I can zoom in and see the distribution and the corresponding question.
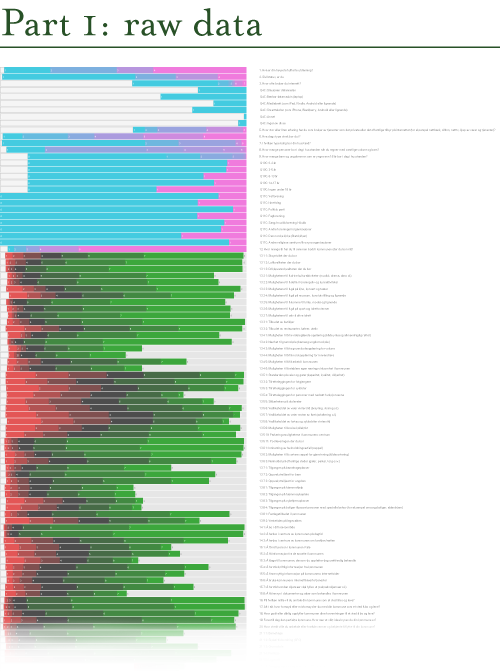
The image shows the top 15% of the visualization. Click to see the full visualization, PDF 1.1 MB
The nice thing with this visualization is that it is possible to see all the data at once. The responses that show a red to green gradient represent likert scale questions (disagree – agree, or very bad – very good). The pink-to-cyan gradients represent all other kinds of questions and variables, in which the categories are more arbitrary. Consequently, it is necessary to know the questions (and possible answers) in order to fully understand the visualization. This would not make much sense to present this for a general audience, but it works well for the purpose of discovery and exploration.
Lesson learned: dbcounter demonstrates how a simple script can be used to create a visualization that would take hours to produce manually. The resulting visualization allows us to see the distribution for all the questions at once, and makes it easier to discover interesting areas in the data, and start asking questions.
Explore interrelations with Parallel sets
While the dbcounter visualization gave a nice overview of the distribution of all the responses, it did not say anything about the interrelations across the questions/variables (also known as cross tabulation). One way of exploring such interrelations is to use an app called Parallel Sets, developed by Robert Kosara. The app makes it easy to interactively explore and analyze categorical data, and show relations between different categories.
The best way to explain this is through an example, using the survey data:
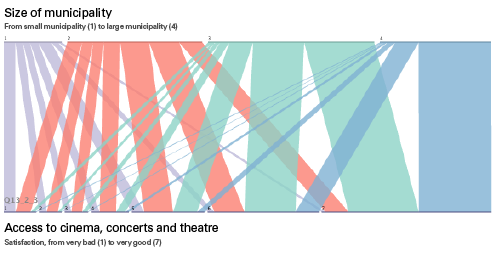
Image exported from Parallel Sets, with text added. Click to see larger image.
The horizontal line at the top shows the distribution of the size of the municipalities the respondents live in, from small municipalities (1) to large municipalities (4). The bottom line shows how satisfied people are with their access to cinema, concerts and theatre, from very unsatisfied (1) to very satisfied (7). Then, each respondent is tracked across the two variables, so that we can see what those who live in a small or large municipality feel about their access to cinema etc. As you might see, most people from large municipalities are very satisfied with the access, while the respondents from the small municipalities are not.
Lesson learned: even though it might be interesting enough to look at individual questions and responses, it becomes more interesting when we start to look for relations across variables. The Parallel Sets app provides one way of investigating such relations visually. However, it seems that this type of visualization works best when there are relatively few categories for each variable.
Searching for patterns in R
While dbcounter and Parallel Sets are great for visualizing data, they provide limited possibilities for analysis. At this point in the project, I was especially interested in correlation, and wanted to look for correlations between different variables in the dataset. For such statistical analysis, R is the place to go. R is a free, programming-based software environment for statistical computing. It can be used for visualizing data, even though the resulting graphs are a bit rough. However, by saving the graph as PDF and edit it in Illustrator, it is possible to make something decent out of it.
I have written some small and simple scripts in R in order to look for patterns in the data, reusing some code examples from Nathan Yau. The visualization type I found most useful was the Scatterplot matrix with LOESS curves. Here, the different variables are mapped against each other, plotting each respondent’s answer according to the two variables. Then, a LOESS curves is drawn horizontally, based on the averages of the variable on the vertical axis.
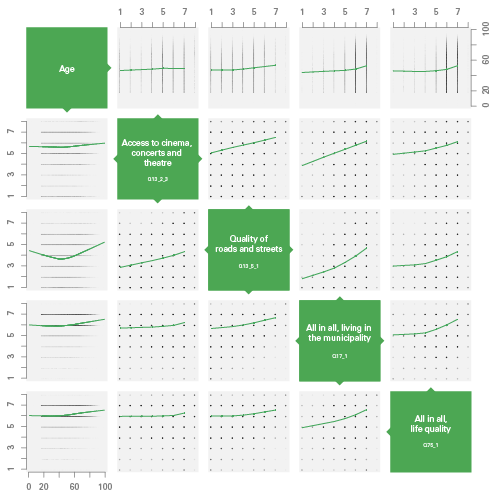
Scatterplot matrix. Click to see larger version (PDF).
In this example, you see the correlation between respondents’ age (top row and left column) and 4 questions. For example, in the left column, satisfaction is plotted vertically against age (horizontally). As you may see, older people seem to be slightly more satisfied than young ones, and young and old people are the ones most satisfied with the quality of roads and streets. In addition, we see that there is a strong correlation between the 4 questions: people who are satisfied with one topic are likely to be satisfied with something else as well.
Lessons learned: data analysis and statistical computing is highly useful and necessary for finding interesting patterns in a data set. As a designer, however, it is important to find the balance between doing statistical analysis and doing data visualization. Even though infoviz designers should know a bit about statistics, it may be more important to know how far our knowledge goes, and when we should talk to a professional statistician. Obviously, this also points to the need for multidisciplinary teams in data visualization projects.
Next up: concept development
To sum up, all the visualization examples presented here have been carried out in order to get to know the survey data, and test different visualization techniques for discovery and analysis. Looking back at all these experiments, I think the most important lesson has been to experience how many different ways it is possible to approach a survey dataset through visualization. There simply is not one type of visualization that can show everything; different types of visualizations provide different types of insights. This also points to the importance of data visualization in general: by visualizing our data in different ways, we see it through different lenses, and thereby learn something new about the data itself.
In parallel to these experiments, I have been working on different ideas for creating a more comprehensive concept for interactive data visualization. This is still very much a work in progress, so stay tuned!
Search
Recent posts
- SpotTrack: Award for Design Excellence
- VizBox Bergen og årets geogründer
- Fulbright report: six months at the School of Cinematic Arts in Los Angeles
- The VizBox Experiments
- TopoBox: exploring a tangible dataviz platform
- Norway in 3D part I: from DEM to 3D surface
- Using visualization for understanding survey data
- Story kicking big data
- Fulbright project: Dynamic Information Visualization
- Visiting Fulbright scholar at USC in Los Angeles
- (E)motional design paper at DANDE2012
- 3,5 års arbeid på 6 minutt og 40 sekund
- PhD thesis online
- New video: Kinetic Interface Design
- Presentasjon: Skisser utanfor boksen